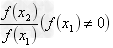对原子向量提取前n个元素,因此分别定义generic_head.numeric、generic_head.character等,另外最好定义一个默认方法捕获不能匹配的其他所有情况:
现在我们还没有定义针对data.frame类的方法,所以当我们输入数据框时,函数会自动转向generic_head.default,又因为提取的数量超出列数,所以下面的运行会报错:
列表可能是创建新类时使用最广泛的数据结构,类描述了对象的类型和对象交互作用的方法,其中对象用于存储多种多样、长度不一的数据。
下面我们定义一个叫product的函数,创建一个由name、price和inventory构成的列表,该列表的类是product。我们还将自己定义它的print方法。
上面我们创建了一个列表,然后将它的类替换为product。我们还可以使用structure():
如果我们创建另一个对象,并将两者放入一个列表然后打印,print.product仍然会被调用:
当products以列表形式被打印时,会对每个元素调用print()泛型函数,再由泛型函数执行方法分派。
大多数其他编程语言都对类有正式的定义,而S3没有,所以创建一个S3对象比较简单,但我们需要对输入参数进行充分的检查,以确保创建的对象与所属类内部一致。
除了定义新类,我们还可以定义新的泛型函数。下面创建一个叫value的泛型函数,它通过测量产品的库存值来为product调用实施方法:
上面我们已经演示了创建S3类和泛型函数的过程,有时候我们需要使用原子向量创建新类,下面展示百分比形式向量创建过程。
首先定义一个percent函数,它检查输入是否是数值向量并将输入对象类型改为percent,percent类继承numeric类:
这里的继承指方法分派首先在percent类中方法找,找不到就去numeric类方法中找。寻找的顺序由类名称的顺序决定。
这里指定quote=FALSE使得打印的格式化字符串更像数字而非字符串。
可惜使用其他函数可能不会保持输入对象的类,比如sum()、mean()等:
但如果我们组合一个百分比向量和其他数值型的值,percent类又会消失掉,我们进行相同的改进:
假设我们想要对一些交通工具,例如汽车、公共汽车和飞机进行建模。这些交通工具有一些共性,它们都有名称、速度、位置,而且都可以移动。为了形象化描述它们,我们定义一个基本类,称为vehichle,用于存储公共部分,另外定义car、bus和airplane这3个子类,它们继承vehichle,但具有自定义的行为。
首先,定义一个函数来创建vehicle对象,它本质上是一个环境。我们选择环境而不是列表,因为需要用到环境的引用语义,也就是说,我们传递一个对象,然后原地修改它,而不会创建这个对象的副本。因此无论什么位置将对象传递给函数,对象总是指向同一个交通工具。
这里的class(obj) = c(class, vehicle)似乎有点语义不明。但前者是基础函数,后者是输入参数,R能够判断好。
注意,airplane的位置是累积的。因为前面说过,它本质是一个环境,因此修改move.vehicle()中的position不会创建一个副本再修改,而是本地修改!
用点滴记录成长为极客R。 =================== R语言学习笔记、数据分析与解决方案、文章转载与资料分享。有些内容属于付费,如果大家觉得有用,希望支持一下。 ================= 反馈与交流: 如果文章内容有问题还请指正,在评论区留言。 如果有一些针对性的疑问,请在创建issue
写在之前 因为简书字数限制,完整版******:如有错误,烦请指正! 第1章 面向过程和面向对象程序设计 1.1 什么是面向过程的编程 定义:一种以过程为核心的编程算法,把问题的过程按照步骤...
1.ios高性能编程 (1).内层 最小的内层平均值和峰值(2).耗电量 高效的算法和数据结构(3).初始化时间app再启动时花费的时间 例如:app启动时可能包含操作: 1.检查版本更新 2.初始化三方地图环信(可能还有******)分享统计 3.游客身...